Retrieval-augmented generation
Retrieval-augmented generation (RAG) makes GenAI outputs more accurate and relevant. RAG works by combining retrieval systems with large language models (LLMs) to produce reliable answers grounded in real-world data. AI-chip manufacturer Nvidia describes RAG as the "court clerk of AI" by showing the user source data they can review, similar to the clerk bringing legal files out of the vaults.
It's becoming a popular method to reduce the hallucinations haunting the wider adoption of AI. The RAG market is forecast to grow from $1.2 billion in 2024 to $11 billion by 2030. Developers are applying RAG in customer support systems and documentation platforms to anchor responses to verified data.
What is RAG?
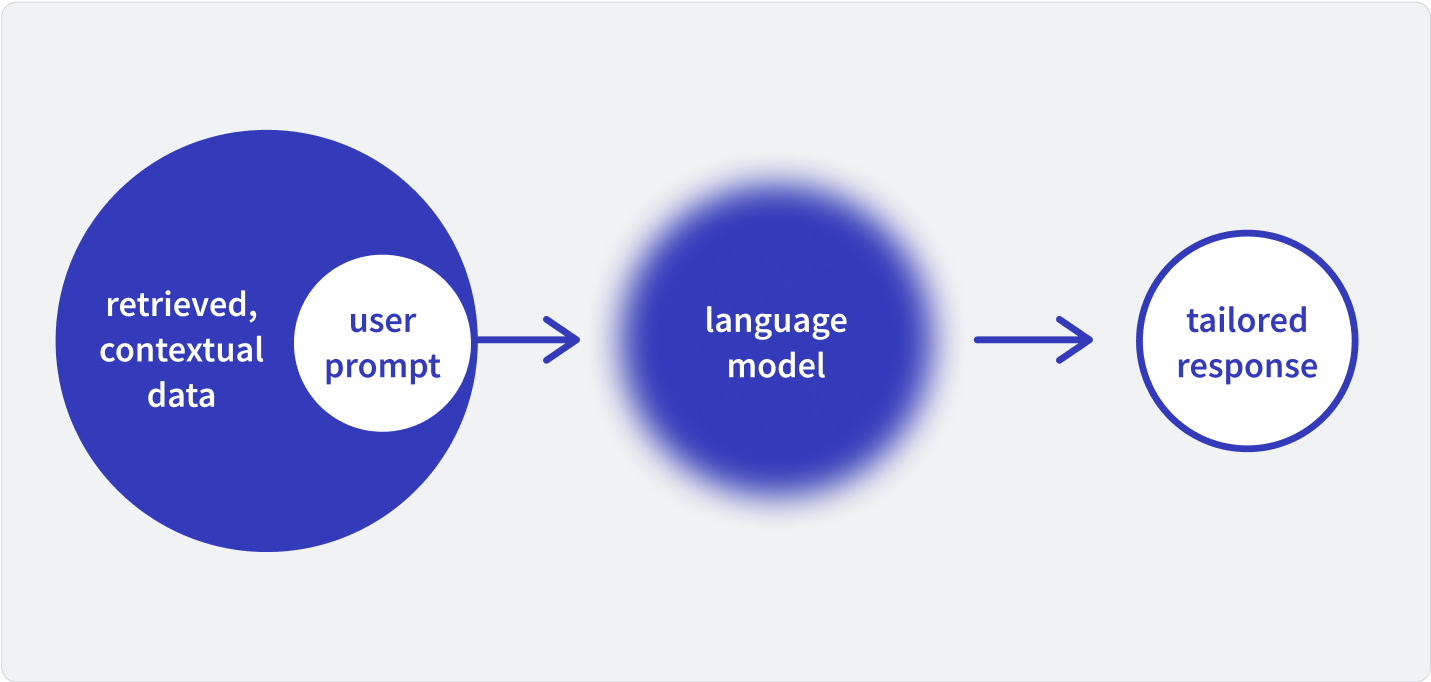
RAG technique integrates two components: retrieval and generation. First, the system retrieves relevant data from an external knowledge source or an internal database. Then the LLM processes this data to produce a context-aware response.
RAG helps developers address challenges with standalone LLMs, like producing incorrect answers or relying on outdated knowledge. It's the ideal technique to generate information and insight from proprietary knowledge, like a dev team's code library or a sales team's case studies file.
Why are developers embracing RAG?
For developers building search tools, customer support bots, or knowledge applications, RAG offers a balance between precision and flexibility.
In addition to trust and accuracy, RAG integrates with large datasets for faster info retrieval. Developers can fine-tune RAG pipelines to produce results tailored to their domain and needs. Unlike pre-trained LLMs whose knowledge is static, RAG can work with dynamic datasets to offer up-to-date responses.
How does RAG work?
There are two stages in the RAG pipeline.
Stage 1 - Retrieve
Tools like Elasticsearch, FAISS, or Pinecone identify relevant data from structured or unstructured sources. Developers typically use vector-based retrieval for similarity-driven searches. When given a query, the system retrieves the top-k relevant documents from a knowledge base.
Stage 2 - Generate
The retrieved data is passed to a generative LLM, such as GPT-4, which compiles a detailed response using the provided context.
Stack Overflow's RAG method
At Stack Overflow, here's how we narrow the dataset.
Step 1: A user asks a question.
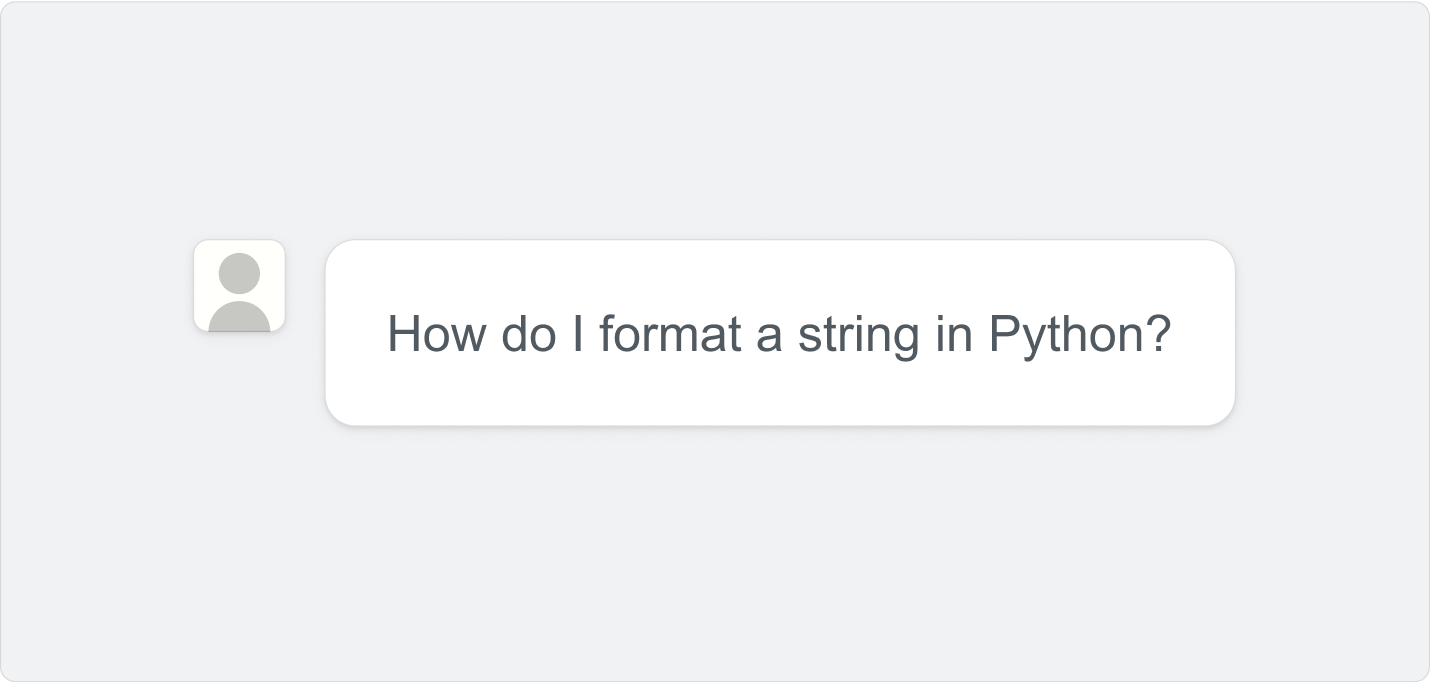
Step 2: The LLM looks only at data from questions on Stack Overflow that have an accepted answer.
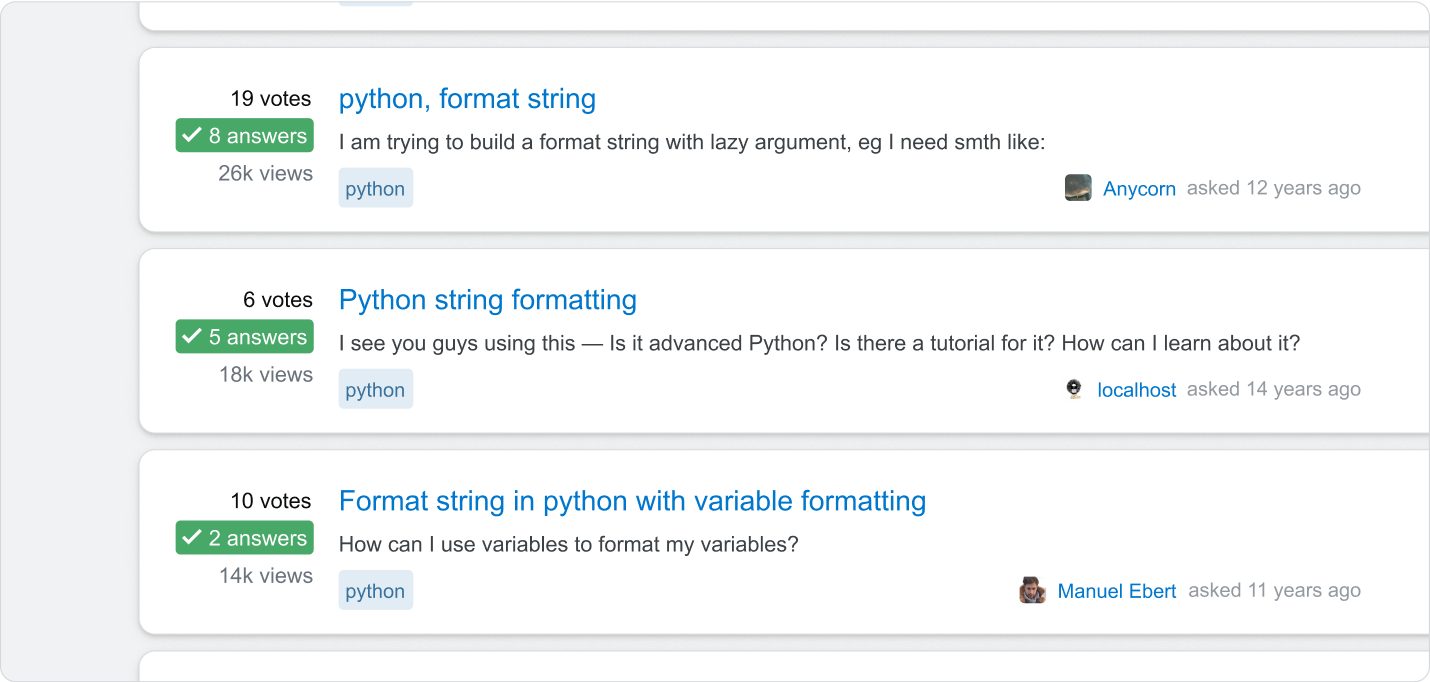
Step 3: The LLM generates a response based on that answer. This answer is a short synthesis of what it has just read and other texts reviewed.
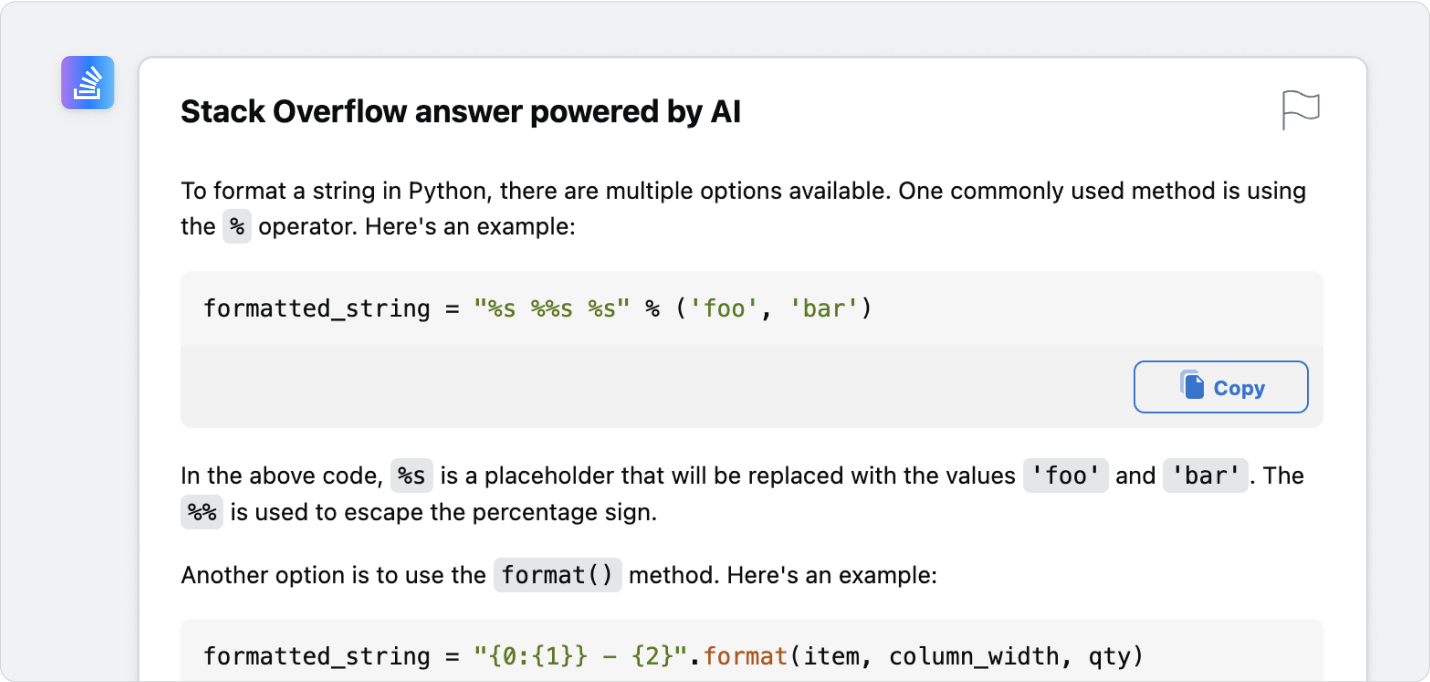
Because it looked at a comparatively small dataset, it provides annotations so users can verify the source material for accuracy and recency.
We use these hidden, system-level prompts to guide the process:
Prompt 1: Take the query and use your large foundation model to process it, tokenize it, and understand it.
Prompt 2: If the query is understood, consult our chosen dataset of Stack Overflow answers.

Prompt 3: If you don’t find valid data, tell the user that you don’t have a viable response.
Prompt 4: If you find valid data to produce an answer, create a short synthesis that provides users with a helpful reply in 200-300 words. Provide links to the data that supports your answer.
Developer tools for RAG
Developers can use a mix of open-source and commercial tools for implementing RAG. Vector databases like Pinecone, FAISS, and Milvus allow fast and scalable retrieval of data points, represented as vector embeddings. These embeddings are numerical formats that capture the meaning of text or data. The foundation of RAG relies on knowledge sources like structured databases, document libraries, or APIs to get the right information to retrieve and process.
Structured data allows search engines like Elasticsearch and Weaviate to provide hybrid retrieval options using keywords and semantic search. Pre-trained LLMs like GPT-4 and Claude or open-source models like LLaMA integrate with retrieval systems to generate responses.
Five avenues to improve RAG performance
Building a high-performance RAG application needs more than just good data sources. Use these five methods to refine your pipeline.
1. Hybrid search
Developers can fine-tune retrieval quality to ensure that only the most relevant documents are passed to the model. This involves techniques like hybrid search, which blends semantic and keyword searches.
2. Data cleansing
Filtering the retrieved data before generation helps remove irrelevant information, reducing noise in the final output.
3. Prompt engineering
Adjusting the prompt and context length can enhance the model’s understanding and avoid overloading it with unnecessary details.
4. Evaluation
Set up repeatable evaluation processes that assess the RAG pipeline and its components. The retrieval stage can be evaluated using metrics like DCG and nDCG, while the generation stage can be assessed with an LLM-as-a-judge approach. Tools like RAGAS help measure the pipeline's performance for consistent results.
5. Data collection
After deploying a RAG application, collect data to improve its performance. This could involve fine-tuning retrieval models based on query-text chunk pairs or refining LLMs using high-quality outputs. Run A/B tests to measure if pipeline changes improve performance over time.
Recent updates to RAG
Retrieval augmented generation (RAG) is likely the most widely-used GenAI technique. It’s been adopted by organizations of varying sizes across disparate industries because it solves a simple problem: How can you use a state-of-the-art model that has information it needs to answer questions specific to your company or institution without the cost of building it yourself?
When we initially wrote about the process of implementing RAG back in January 2024, we were describing what is today known as naive RAG. This isn’t a slight we take personally; rather, it speaks to the rapid advance of this field and the wide array of techniques and tools that have been built upon the foundational approach we discussed a year ago.
Naive RAG
In a naive implementation of RAG, a user query is used to retrieve relevant documents, after which the prompt is fed to a model that delivers an answer. In more advanced versions, the system might take the user’s original prompt and enhance it—rewriting it or expanding it—before matching it with relevant documents. This takes a lot of the burden off the end user, who may not be familiar with GenAI or prompt engineering.
A key benefit, even with naive RAG, is that the dataset the AI model uses at inference time can be regularly updated. It is quite expensive and time-consuming to retrain or even fine-tune large AI models with fresh data. RAG solves for this, allowing models like ChatGPT to search for news stories or stock market data needed to answer questions about current events. Inside an organization, this same principle can be applied to ensure your GenAI agent is up-to-date with any changes to your codebase or documentation. For a customer service agent or medical providers, this could be used to ensure communications from previous support chats or consultations are included as context in a following session.
A second stage employed in advanced RAG takes place after the information is retrieved. When an LLM system has to produce an answer based on a large set of documents, it can suffer from a form of information overload, causing it to leave key context or insight out of its response to the user. More advanced systems use AI agents to rank the material in terms of the best match, summarize long documents into shorter, more digestible chunks, and fuse various source materials together to provide the richest context. The information is then fed as a prompt to the model and an output is provided that delivers more value to the end user.
Modular RAG
In modular RAG, the techniques of advanced RAG are taken a step further. The system might have a step that first looks at the relevant documents, reasons over them, and distills the key high-level concepts and abstractions. It can then use these to guide its evaluation of the source material, improving the chances that the final answer won’t be constrained by a small subset of specific documents. Other techniques break the user’s initial question into a series of smaller questions or produce a hypothetical answer that is used to help find the best source material.
Security vulnerabilities
As RAG becomes a more commonplace technique, it provides a large and novel attack surface for bad actors. Studies have shown that it’s possible to inject malicious text or code into the source material a RAG system might draw on. For example, if an open-source code library is commonly referenced by a RAG system when generating answers to questions about software development, attackers might add a backdoor that allows them access to systems which adopt code from this library without running it through the property security checks.
Data quality and RAG
In this edition of our Industry Guide to AI, we’re examining the state of GenAI through a lens of data quality. And the most important ingredient in a great RAG system, regardless of how simple or complex, is the quality of the data it’s searching for when trying to provide an answer to a user’s question. This means organizations with well-organized knowledge and codebases have an advantage in the GenAI era.