Large language models

The AI tech that captured the public's imagination over the last year is large language models (LLMs). An LLM is a massive deep-learning model that can effectively create large chunks of text or programming code just from simple natural language input. It’s as close as we have to the science fiction trope of talking to computers.
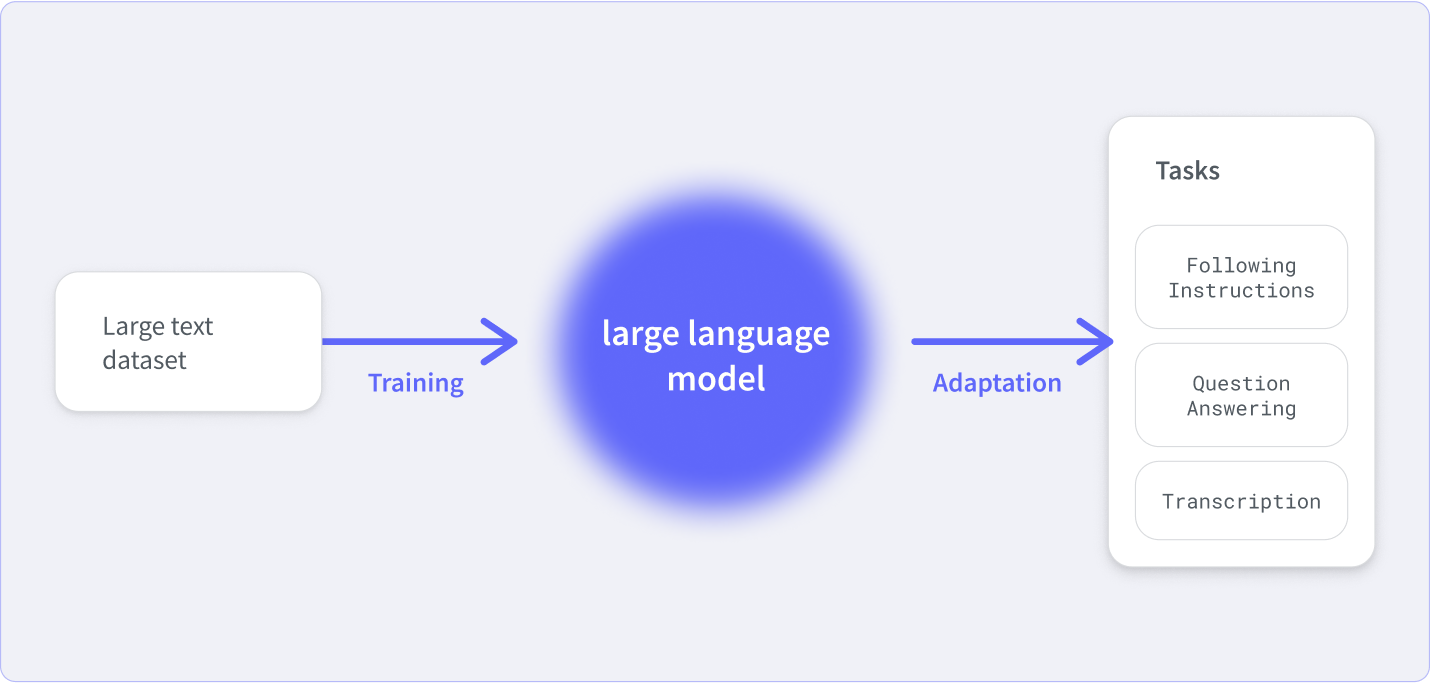
LLMs work by predicting the next word that should come in a sentence based on a prompt. However, they are trained on a massive dataset of text, so they are able to understand, generate, and sometimes translate documents' worth of text at a time. As their training data and the number of parameters they use grow, LLMs are able to perform new tasks (like identifying a movie from an emoji string) without additional programming.
Most LLMs use the Transformer architecture, which is an encoder-decoder neural network that uses attention. This attention allows the model to link to different parts of the input text when making predictions, so it’s able to create associations between concepts that might not be located near each other in a piece of text. When trained on large corpuses of data, that means the architecture can connect concepts across inputs.
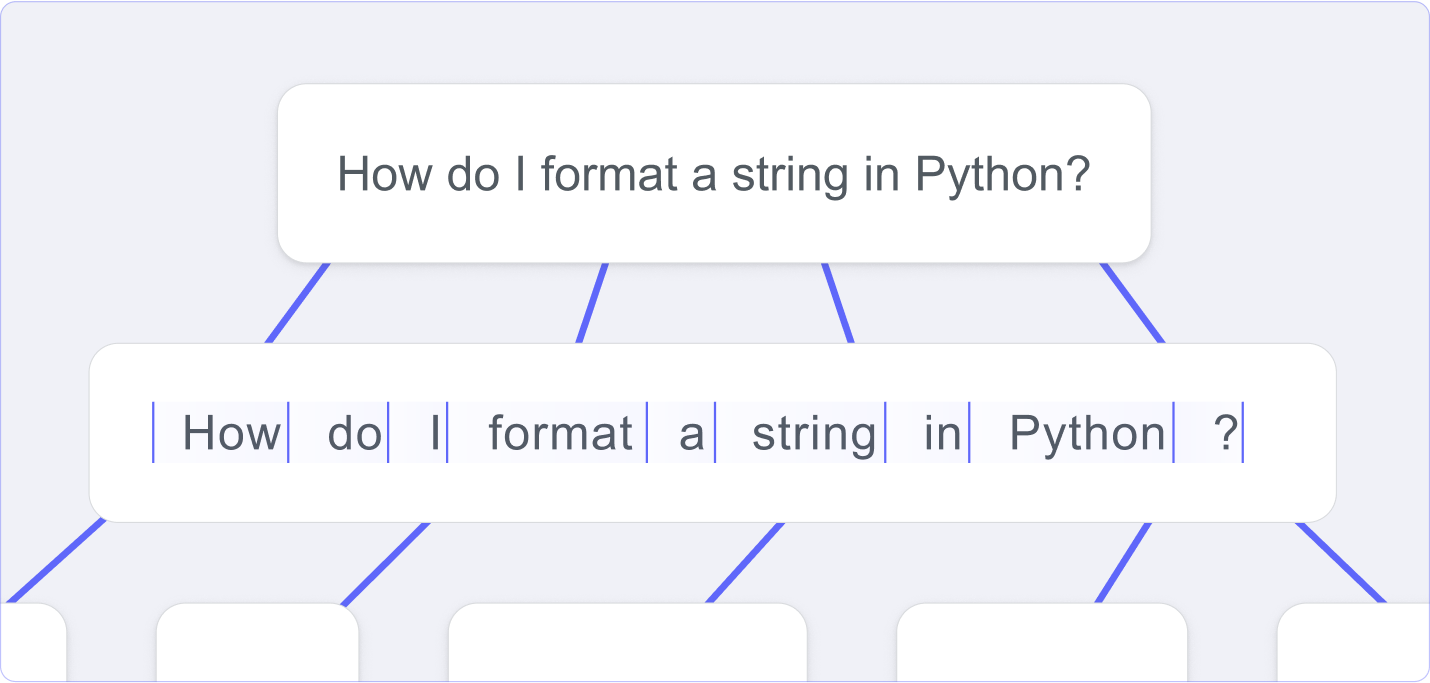
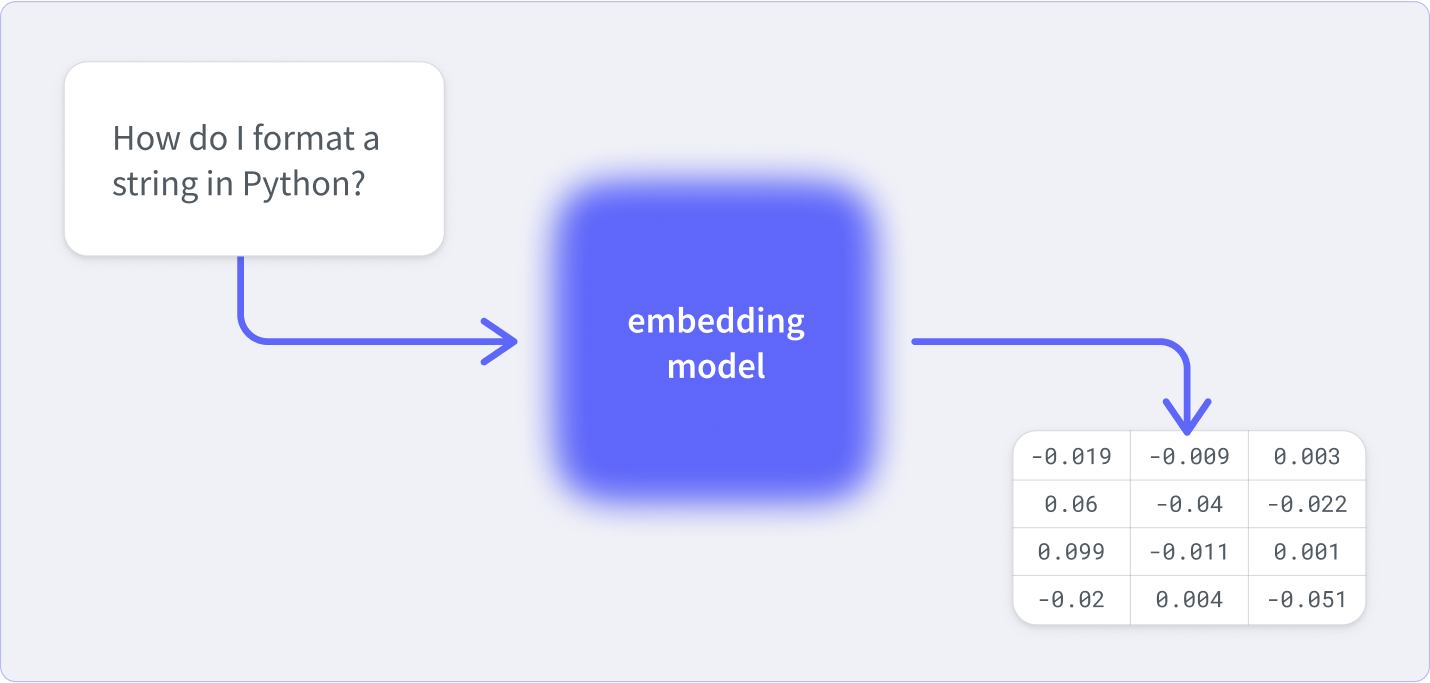

During training, this architecture converts chunks of text—called tokens—into n-dimensional vectors that represent the semantic meaning of that text within a space. These have hundreds of dimensions, so it’s not something you can easily visualize, but you can use math to find the shortest path between two vectors and determine how close their meanings are.
When processing these vectors for an LLM, the model adjusts the weights and biases for billions, sometimes trillions, of parameters so that its predictions reflect the actual text used in the training data. These parameters aren’t values or categories that you can put a name to, but they’re the things that allow for accurate predictions. More parameters let the model predict language with greater complexity and nuance.
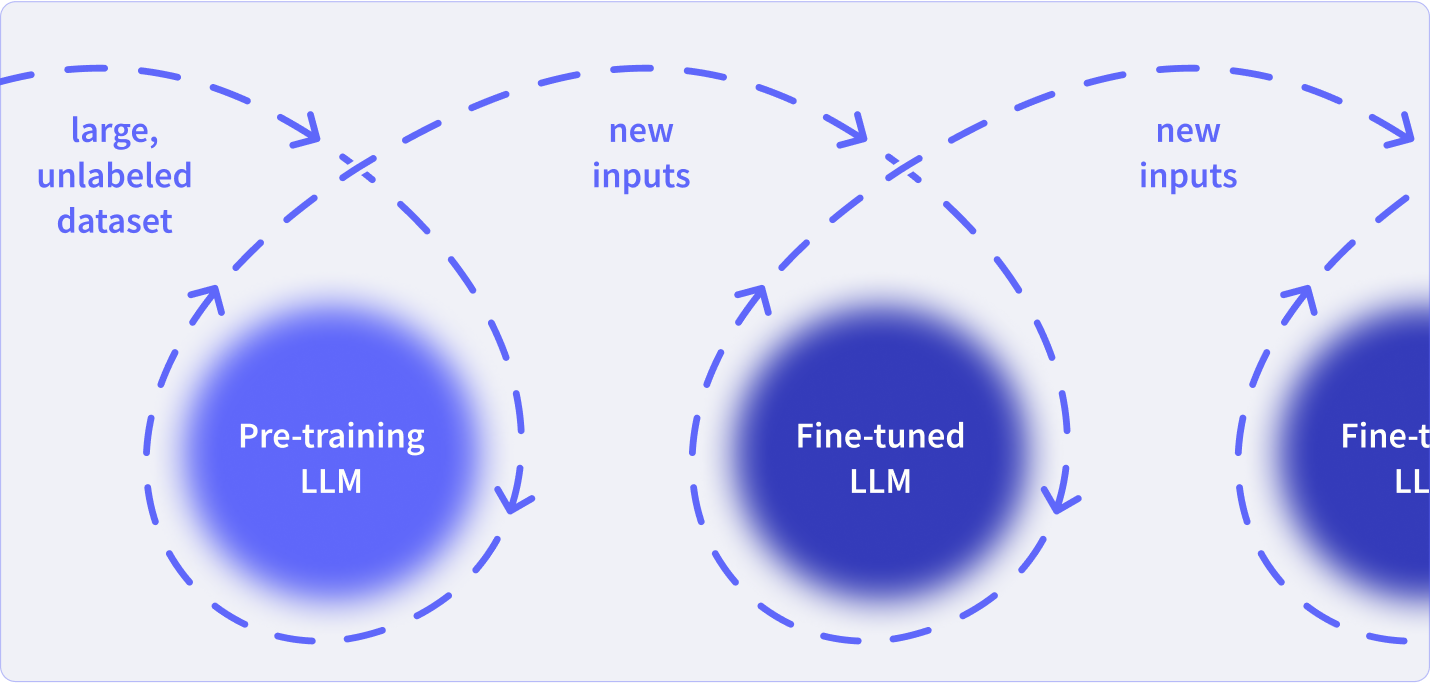
Once an LLM has been deployed to production, you can continue to update its data using fine-tuning. This process updates the model parameters to reflect new inputs. You can do this on new data added to your databases, user prompts, or other real-time data streams. This can update your data as contexts change, avoiding model drift.
An LLM will reflect its training data, so it is at risk of propagating the same biases and beliefs of the humans who created the data. You can pass prompts and LLM output through additional LLM stages to remove any toxic or otherwise problematic text.
The ability of LLMs to understand and generate human-like text is a remarkable development for software engineering and humanity as a whole. They are an area of active research and have limitations, but through careful and thoughtful implementation, they can add powerful GenAI features to your software.