Large language models
Large language models (LLMs) are now widely accepted; uptake has increased with business and consumer users. According to McKinsey's 2024 report, 65% of global organizations are actively using GenAI tools, double the uptake from a year prior.To most users, they're more commonly known by LLM brand names like OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude. LLMs are trained on large datasets and fine-tuned to generate, summarize, and translate, and can now do much more than text-based tasks in a chat window.They're becoming multimodal, meaning they can process and generate multiple data types, including text, images, and video from a text, visual or audio prompt. Google’s Gemini and other models can interpret and combine diverse inputs to create visuals and animations in addition to text.
New interfaces like ChatGPT's Canvas feature let end users fine-tune and revise initial outputs, allowing users to leverage the tool for end-to-end content creation.
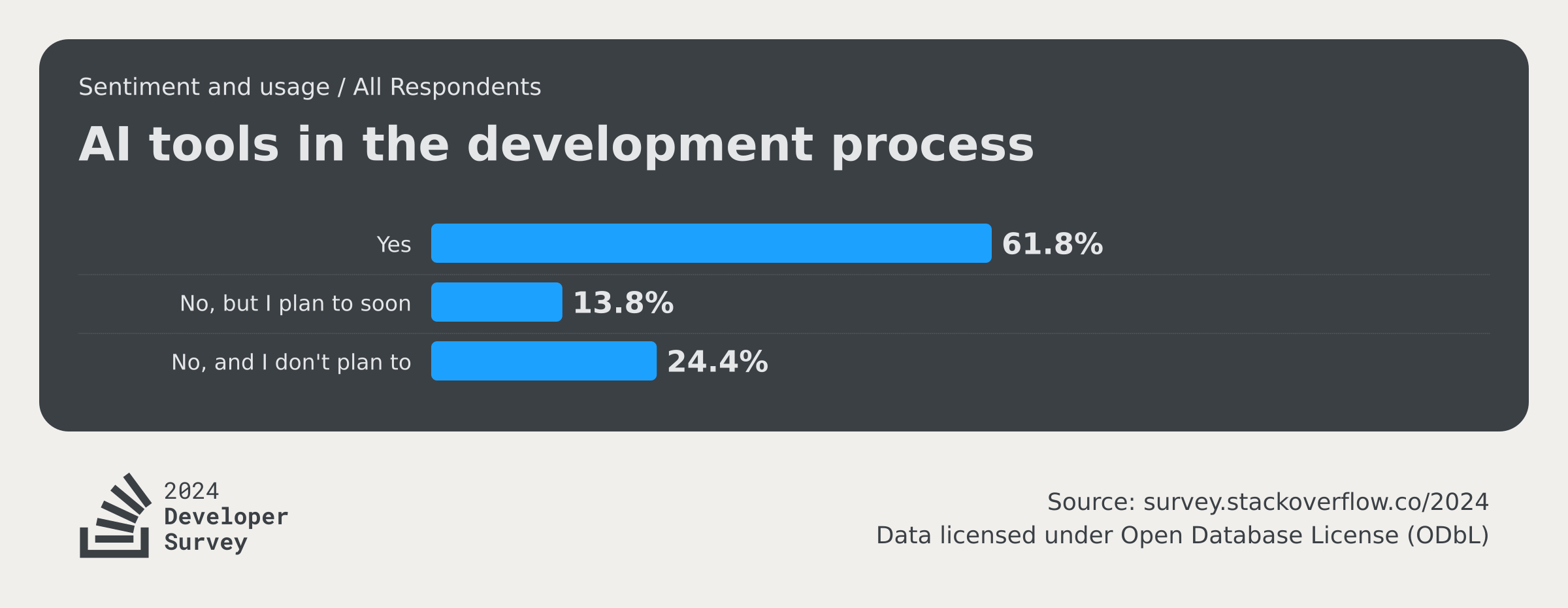
Three in four developers are now using LLMs
LLMs are reshaping developers' workflows by automating code generation and debugging. Tools like GitHub Copilot offer real-time coding suggestions, making development faster and more efficient.
They're now widely adopted in software development. According to our 2024 Stack Overflow survey, more than three in four respondents (76%) use or are planning to use AI to assist with coding, up from seven in ten (70%) in 2023.3
Understanding LLM explainability
A core challenge with LLMs is understanding how they produce specific outputs. This concept, explainability, identifies the reasoning behind a model’s predictions. It helps determine why an LLM makes certain suggestions and ensures outputs meet expectations, reducing unexpected results and bias.Explainability is an evolving and critical aspect of responsible AI practices. Efforts are growing to improve the trustworthiness and usability of AI systems, keeping them from becoming black boxes whose internal workings are not visible or easily understood. If you’re explaining how LLMs work to a non-technical audiences, try this analogy:
LLMs are like advanced Google search autocomplete systems that guess what word you may want to see next. They learn this by training on patterns from huge datasets. They generate outputs as predictions based on prior data, not explicit understanding of the task, and they don't understand the meaning behind the words they produce. Mistakes, or hallucinations, occur when the model produces plausible but incorrect information.
For more ways to talk about LLMs, see our guide explaining generative language models.
The evolving architecture of LLMs
Despite advances in capabilities, the underlying architecture of LLMs has remained relatively stable. Models still largely rely on the transformer architecture introduced by Google in 2017. Newer techniques enhance efficiency and scaling. Our LLM analysis highlights the reality that improvements typically come from refining data and training methods. Deployment optimization also plays an outsized role in enhancing LLMs’ performance.
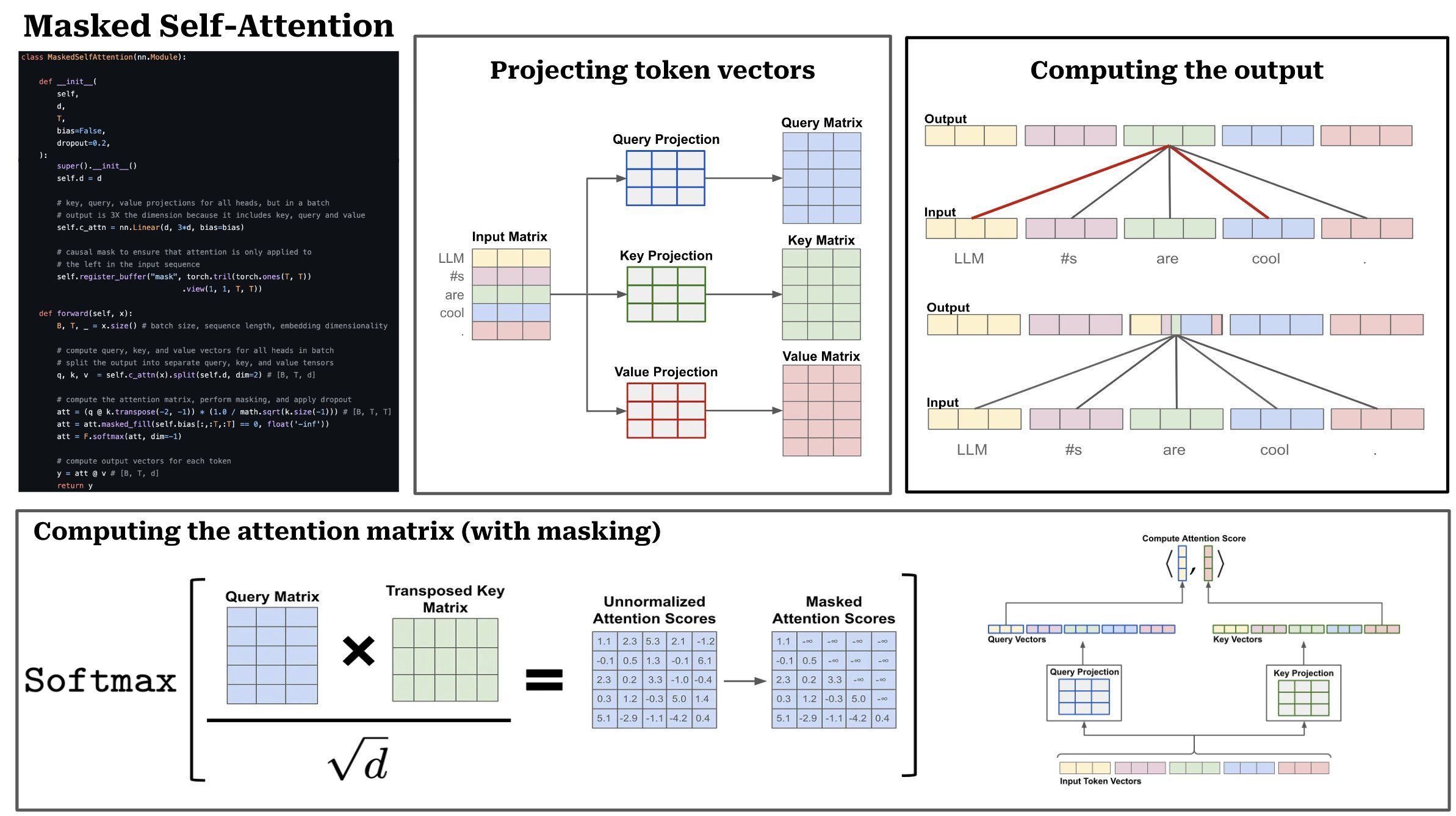
How LLMs learn relationships with masked self-attention
A core principle of LLMs is a mechanism called masked self-attention, which allows models to understand relationships in a sentence between tokens (words or "subword" fragments). Instead of processing text sequentially, the transformer architecture allows LLMs to consider multiple tokens simultaneously, assigning attention weights to focus on the most relevant parts of the input.
In the sentence “The developer fixed the bug,” for example, the model identifies that “developer” and “fixed” are closely related. By masking parts of the data during training, the LLM learns to predict missing tokens (in this example, words) and better understand context. This process is core to the model’s ability to generate coherent and relevant outputs.
For a detailed breakdown, explore our article on masked self-attention.
Parameters and precision
You may have seen a couple of numbers thrown around in regard to LLM size and power: numbers of parameters and precision. Together, these correspond to the accuracy and capabilities of a model, as well as its storage size, resource requirements, and cost to run.
Parameters are the various biases and weights that are adjusted during training and fine-tuning. Each parameter is a vector—an array of hundreds of numbers. More parameters let the model make deeper connections and can lead to emergent abilities. Cutting-edge models have hundreds of billions or even trillions of parameters, though not all parameters will be used for every request.
Precision refers to the size and accuracy of each number with a parameter’s vector. They are described in terms of the amount of memory they take up—for example, 32-bit or 8-bit—and the form of the number—for example, floating point or integer. A high-precision model using 32-bit floating point values will be more accurate but require more resources than one using 8-bit integers. High-precision models can be quantized down to lower precision levels by reducing the amount of information (say by rounding to a higher decimal point).
The assumption that more parameters and higher precision always result in better, more accurate responses is being challenged. Smaller models have shown comparable results by training on targeted data or limiting responses to some knowledge domains. Lower-precision models have shown themselves competent in answering many common questions. Recently, DeepSeek released a reasoning model that disrupted the LLM market by doing both.
Key considerations for developers
LLMs can generate incorrect outputs, known as hallucinations, so verifying results is critical in applications where accuracy matters (and where doesn’t it?). Fine-tuning and prompt engineering are effective ways to optimize performance and tailor outputs for specific tasks. Understanding explainability, or the degree to which an AI system’s internal workings can be explained in human terms, is essential for building trust and encouraging broader adoption. As LLMs continue to advance, developers will play a vital role in refining and responsibly integrating them into development workflows.