The rise of GenAI and LLMs
The birth of the transformer
Neural networks have become the leading approach to AI. Prior to ChatGPT, they were recognized for breakthroughs in image recognition, natural language processing, and gameplay. Until recently, however, they rarely created anything original. Instead, they mastered a specific task or system.
GenAI ventured into new territory: a neural network system that could create something unique in response to a user prompt. Systems like DALL-E and Midjourney could generate images in response to input from users. In 2017, researchers at Google published a paper proposing a new architecture for neural networks: the transformer. This approach allowed networks to scale to much larger sizes and make better use of compute provided by graphics processing units (GPUs).
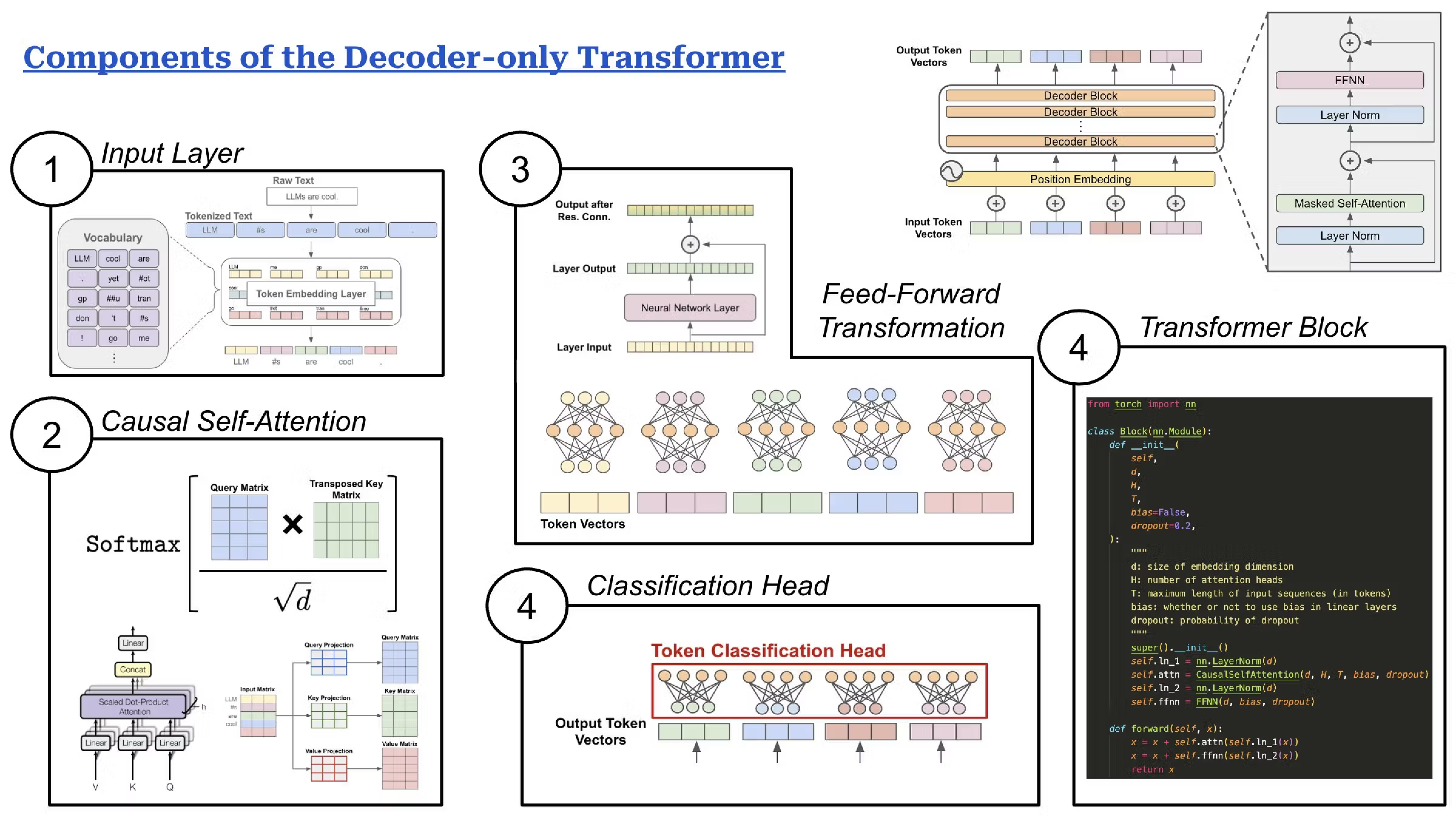
The transformer opened the door to the large language model (LLM), a generative system trained on text to respond in kind. In 2018, five years before ChatGPT burst onto the scene, OpenAI released GPT-1, where GPT stands for generative pretrained transformer model. When prompted, GPT-1 could generate coherent sentences and even paragraphs. But it also made mistakes and often wandered off-course. The subsequent releases of GPT-2 and 3 made big waves in the world of data science and AI, but they didn’t generate any mainstream recognition.
The arrival of ChatGPT (roughly GPT 3.5) was a watershed moment. Something about the scale of the training and the subsequent work to finetune the system through reinforcement learning and human feedback produced a GenAI that was accurate, knowledgeable, and rational enough to capture the world’s imagination.
Today’s neural networks have achieved a staggering scale in just a few short years. Systems like ChatGPT, Google’s Gemini, or Anthropic’s Claude are estimated to train on a once-unfathomable amount of text (more than 10 TB of internet data!) that continues to scale. These AI companies use special-purpose compute clusters composed of tens of thousands of high-end GPUs to train their AI models on this raw material. The process that can take weeks or months and cost tens of millions. But, as we’re seeing, the results can be transformative.
The capabilities of LLMs are soaring
Multimodal AI
Since we published the first edition of this guide, foundational GenAI models have improved in their ability to reason and converse. We’ve seen the emergence of multimodal AI models like Google’s Gemini, which is capable of understanding and creating content across mediums: images, audio, video, and text. Open AI’s GPT-4o also reasons in real time across images, video, audio, and text. For example, a multimodal model can receive a photo of a smoothie and produce the recipe (and the other way around).
Multimodal AI has enormous potential to transform nearly every aspect of how people live, including how software developers learn and work. Multimodal AI models are less like software programs and more like consulting experts or assistants. They don’t just tackle toil (although they do an impressive job of that); they provide guidance via organic, humanlike interactions.
Reasoning LLMs
We’re also seeing a new series of reasoning models trained with reinforcement learning to think through hard problems. These models, like OpenAI’s o1, represent a pivotal evolution in how AI solves problems.
The difference between reasoning models and a model like GPT-4o is the difference between someone who has memorized their times tables and someone who understands the principles behind multiplication and can apply them in new contexts.
These models are trained using chain-of-thought prompting that mirrors a human approach to problem solving. Chain-of-thought prompting breaks problems down into manageable chunks of data that can be arranged sequentially to lead to an answer, like stepping stones across a stream. This makes reasoning models like o1 ideally suited for jobs that require complex, logic-driven problem solving, like STEM research or advanced coding projects. Research has shown that chain-of-thought prompting significantly improves LLMs’ ability to perform this type of reasoning.
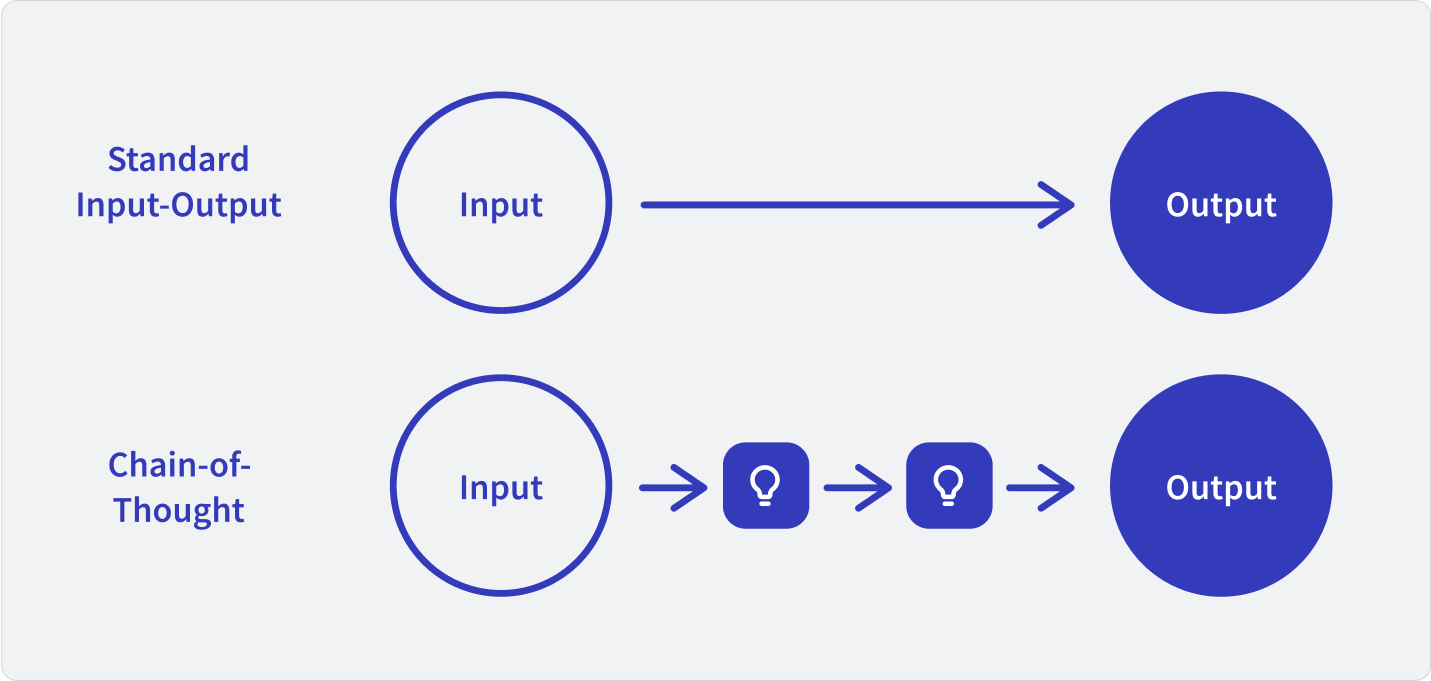
Reasoning models are high-latency compared to real-time models that respond in literal milliseconds. GPT-4o, for example, is up to 30x faster than o1. And they’re not just slower; they’re also more expensive. o1 costs $60 per one million input tokens, while GPT-4o costs $15 per one million.
Higher token limits
Another major factor behind the continued improvement of AI models is their higher token limits. Tokens are the pieces of text the model uses to process language, with the number of tokens dictating the amount of information the model can use in its reasoning.
Both OpenAI’s GPT-4o and Google’s Gemini 1.5 Pro boast high token limits that allow them to manage and understand much bigger pieces of text within a single interaction. Higher token limits enable us to use AI for more complicated, data-intensive projects than were previously feasible, with no need for extensive fine-tuning of the model.