Integrating your existing tech stack
Implementing a GenAI program in your organization is a big challenge, but so is integrating that program with your existing tech stack. Depending on your use case and the technologies that you’ve chosen, GenAI could be as simple as a few new API calls or as complicated as a series of new dependencies, including databases. How you approach this integration depends on the complexity of your GenAI use case and the existing pieces in your software stack.
In a lot of ways, adding GenAI to a software stack is the same as adding any other dependency or service. You need to manage how it connects to the rest of the program, how it gets deployed to production, the infrastructure that it runs on, and how you monitor and test it.
Connect

If your integration just uses API-based LLMs, then all you need to do is make sure the right data gets into the payload and you handle the responses. That’s simple. If you’re sending proprietary data, then you’ll want to implement the appropriate security measures.
For most other use cases, you’ll at least need some Python support, whether directly or by using Python wrappers. Python is one of the main languages for machine learning tools, so to use the tools, you’ll need to use Python. Some tools, like PyTorch, have official frontends for other languages, but most will require a little connection between it and your main code.
Those connections can be direct references to Python or they can be through programmatic interfaces like APIs, RPCs, or event queues. If you’re working in a multi-container cloud, these interfaces may be a better way to go. ML processes and general application code may have different memory and compute needs, so deploying them to different containers may yield better cost and performance results.
Deploy
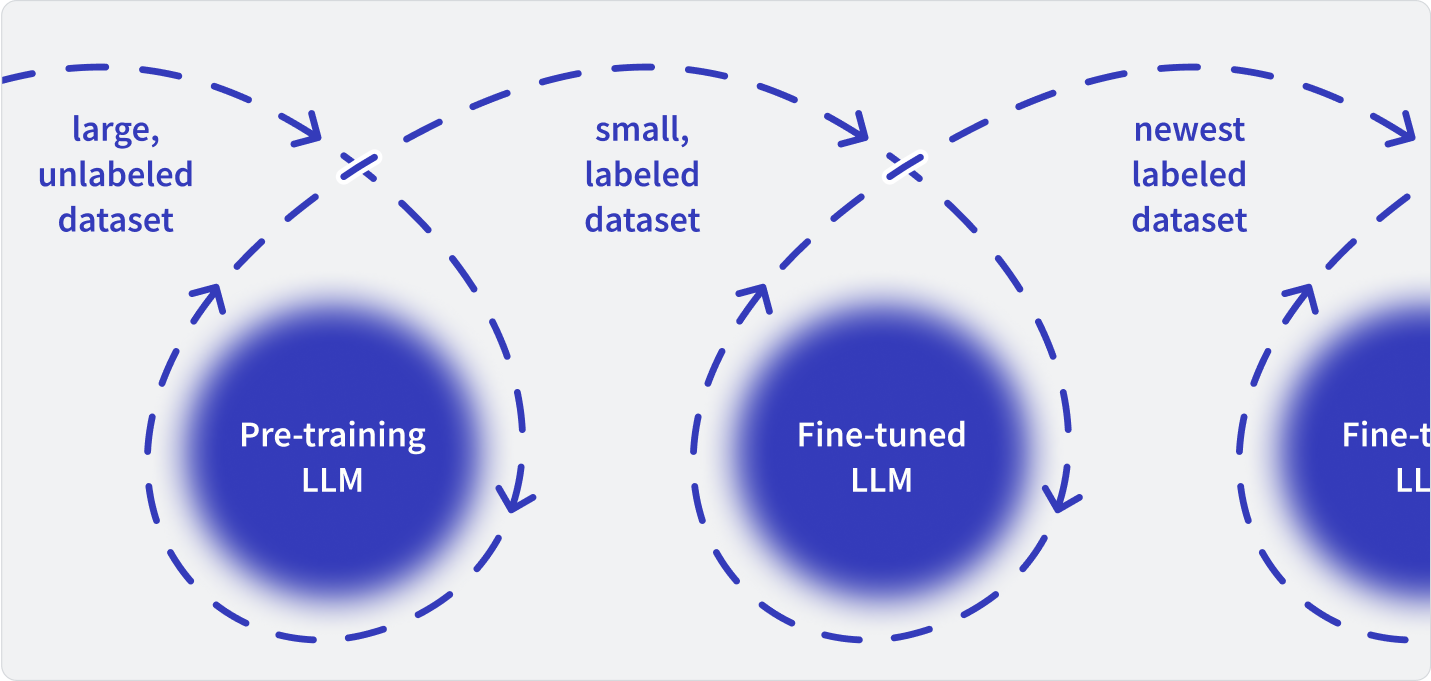
While you may think you can deploy an ML model using your standard CI/CD pipeline, it may be a little more complicated. Models are just sets of weights and parameters; GenAI uses an algorithm on top of that to make predictions and generate text, images, and more. Unless you’re using a general-purpose LLM and never need to update, you’ll likely inference data for fine-tuning, probably from a production or analytics database. You may even configure the LLM to “reason”: that is, to pull in additional data when processing the prompt and step through a multi-step prompt refining process. Both mean your model may need to access data and process it after deployment. You may also need a process to update the existing models.
Your model deployment may start to look like and integrate with your data pipelines. Data gets extracted from existing sources, transformed into something clean and usable by the inference algorithms, and loaded into the model as adjusted weights and parameters. There are a few tools—TFX, KubeFlow, and others—that will simplify and manage this deployment.
Alternatively, if you’re using retrieval-augmented generation or semantic search, your pipelines will be vectorizing new data and storing it where the GenAI processes can get it.
Build infrastructure
Managing your GenAI infrastructure may be as simple as scaling up your existing cloud solution to provide additional resources. However, GenAI processes tend to use massively parallel compute—GPUs and TPUs—so you may need to run these processes on servers with different configurations. It might even make sense to use multiple architectures in your servers.
Using infrastructure-as-code, containers, and container orchestration like Kubernetes may make things a little more manageable—and more complicated. More manageable because these tools can handle deployments across multiple server types and architectures. More complicated because these tools are another layer that you’ll have to manage. It all depends on what you’re already using and what your cloud provider offers as managed services.
Monitor and test

While many folks see LLMs and other deep learning models as black boxes impenetrable to observation, there are ways to monitor and test them. The simplest is storing prompts and responses. You can perform additional analysis on these to check for sentiment, toxicity, and prompt leakage, often using another LLM.
ML models can—in some ways—be treated like another program, so you can monitor their performance in production in the same terms as you monitor other services: number of requests, error rates, response time, and so on. LLMs can be especially costly, so monitoring token usage and overall costs is important.
Testing is a matter of running prompts and observing the output. You can automate these tests by chaining them to an evaluator LLM that is trained to determine whether the responses meet some given criteria. Include in these tests adversarial prompts, which are designed to produce harmful behaviors or bypass security controls.