The importance of data quality

Chatbots from OpenAI, Google, and Anthropic know a lot—heck, they basically read the whole internet. But to be truly useful inside your organization, a GenAI assistant needs to get at the proprietary knowledge your employees use to get work done. Below we’ll cover the process of adding your information to a database the AI assistant can draw on, either by fine-tuning a model on that data or incorporating it into a process called retrieval-augmented generation (RAG).
What kind of data should I feed my LLM?
The first question you’ll need to ask yourself is how you want to deploy a GenAI. If you plan for it to be a helper inside your work chat, then it might make sense to train it on your organization’s documentation. If it’s going to act as tech support for your customers, you could train it on your FAQ and the forum posts from your technical support website. A GenAI trained on your codebase might prove useful as a productivity booster for your developers and a system trained on your HR and payroll materials might be something employees can turn to with questions that would normally be routed to your HR team.
Does data quality matter?
One of the biggest themes to emerge in the GenAI space has been the importance of data quality. When Google released its latest model, Gemini, they wrote that “data quality is critical to a high-performing model.” We know it's an important component of training, alongside the algorithms that guide the process and the hardware that executes it. But what many industry leaders are now saying is that data quality trumps these other factors.
Tri Doa, who teaches computer science at Princeton University, said:
“All the architecture stuff is fun, making the hardware efficient is fun, but I think ultimately it’s about data. If you look at the scaling law curve, different modern architectures will have the same slope, just a different offset. The only thing that changes the slope is data quality.”
Making it happen
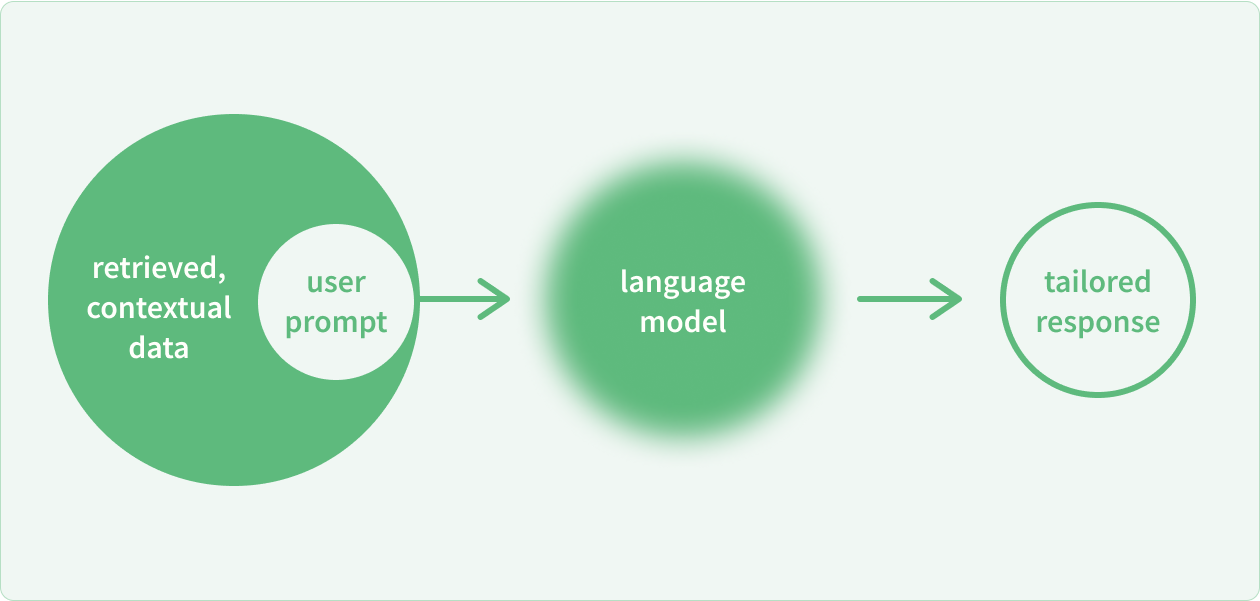
The method quickly becoming an industry best practice for getting a GenAI model to work with your data is called retrieval-augmented generation (RAG). With this method, the GenAI system retains all the intelligence of its training and fine tuning, but restricts its data set down to the information you provide, allowing it access to proprietary knowledge and helping to reduce factual errors.
To take this approach, you’ll need to pick an embedding model and store the resulting vectors in a vector database. In layman’s terms, you turn text into numbers organized as points in a spatial cloud. By learning which terms are related, the model comes to understand their meaning and context.
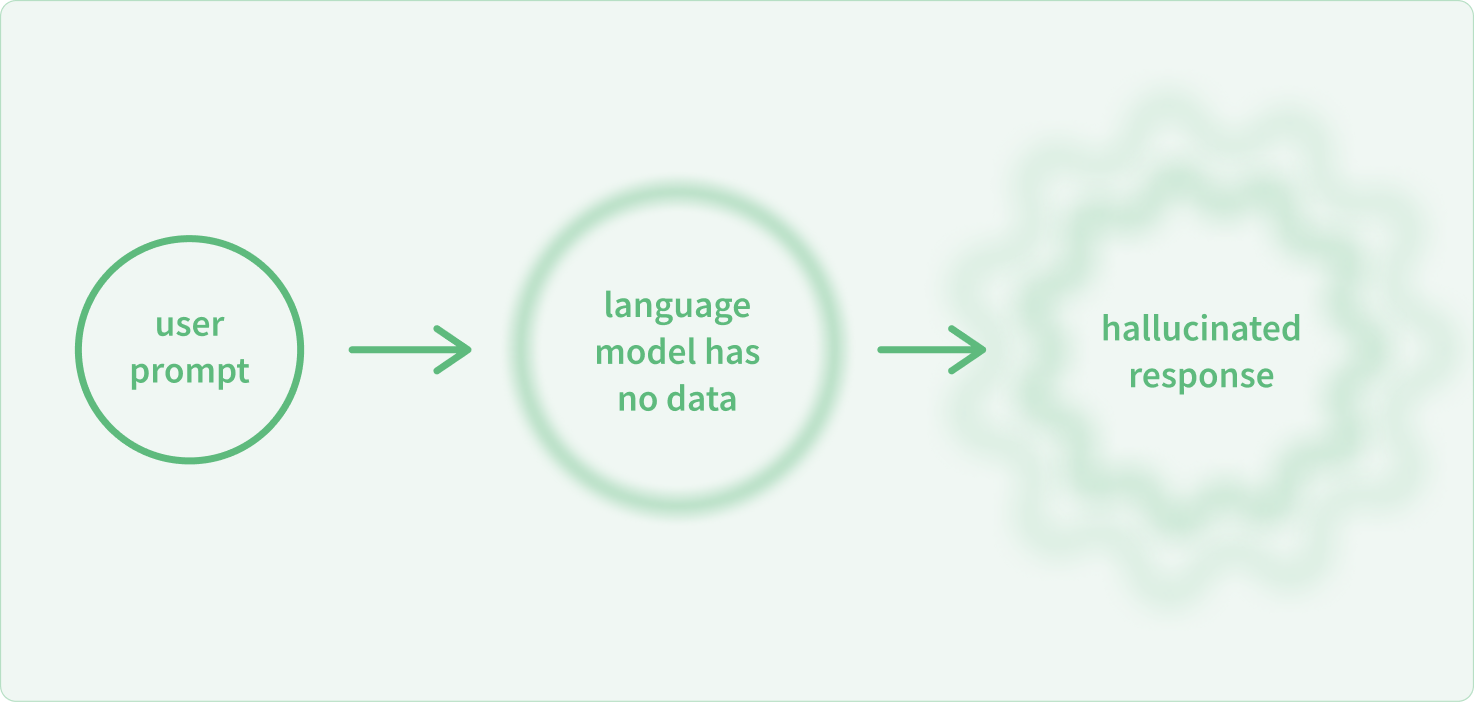
A great RAG system allows you to reduce the factual inaccuracies and hallucinations an LLM can produce, and also gives you the ability to include annotations, so that users can see the ground truth the LLM assistant used to provide its answer to each query.
Conclusion
A lot of GenAI assistants are going to be built as chatbots that provide answers to users’ questions. At Stack Overflow, we’re lucky that our approach to documentation was already organized as a Q&A system. Moreover, this information is also packed with rich metadata—which answer is the most recent, which answer got the most votes, which answer was accepted, and what tags are associated with this question.
A crowdsourced system has another advantage: data quality. If an AI is pulling in a huge amount of internal documentation or lines of code, it has no way of knowing which information is most accurate, relevant, and up-to-date. It might be great at understanding the text from your wiki or the code from your repos, but it has no way of knowing which parts of the wiki have gone stale or which code is due to be deprecated unless you provide that context.
If you’re working to create a GenAI assistant at your organization that will have access to proprietary information or code, make sure you spend time with your data science team figuring out how to clean and improve its quality before using it for training, fine-tuning, or RAG. Also, be sure to check with your legal and security teams to ensure that any data which isn’t meant to be widely available is excluded from training, as there is no way to remove it when the model has been finished without starting the training process all over again.